Data-Driven Attribution
 Updated
by
Mikkel Settnes
Updated
by
Mikkel Settnes
Data-Driven Models replace specific business rules with a mathematical algorithm, that uses data from all the journeys to dynamically determine what touchpoints influenced the given Stage and therefore should receive credit.
The benefit of rule-based models are the explainability. You can look at a single customer journey and follow the rules of the model and understand the credit scoring. On the other hand, the Data-driven models consider all the journeys at the same time. This makes the model able to reason about what the journeys have in common, but at the cost that you can no longer understand the attribution fully by looking at a single journey. Thus, unlike rule-based models such as time decay, Dreamdata's Data-driven attribution model's algorithm dynamically determines credit, rather than assigning more weight to recent interactions based on a fixed decay function.
When should I use the data-driven attribution model?
The rule-based models are limited to consider only a single journey at a time and follow a fixed and pre-defined rule-set.
The Data-driven model defines its own rules when looking at all your journeys at the same time.
Also consider the Data-driven attribution model if:
You have longer journeys, where it is not clear that a special action is most important, and you do not need to be able to follow the "rules" made by the algorithm.
It is important to note that rule-based models, when summed for all journeys, will also give a picture of what is typically happening.
The difference is that the data-driven attribution model will adjust the weighting of each touchpoint based on how frequently it appears.
Example
The data driven model will not give as much attribution weighting to this touchpoint if it does not appear in journeys that reached the selected stage.
When you want to better follow the rules of the algorithm or there are actions along your journey that you care more about: consider combining the Data-driven model with custom rules or setup special exclusions to better guide the algorithm. This is done in the data hub --> attribution model inside your Dreamdata instance.
Do I need a specific amount of data?
The Dreamdata Data-driven model can be applied regardless of the size of your data.
When you have limited amount of data or journeys with a low amount of touchpoint, the Data-driven model will be close to a Linear attribution model.
The Linear model represent the fair sharing of credit in the absence of information that makes some touchpoints worth more than others. This is why the Data-driven model goes towards the Linear model in cases when the number of journeys are below 50.
Note that the journey is only useful to the algorithm if it has more than one type of touchpoint. If only a single type of touchpoint exist in the journey - the attribution is not affected by any attribution model.
In such cases, you expect to not have conclusive evidence that credit should be shared in another way than equal.
Data-Driven attribution based on Markov chains
The data-driven attribution models within the Dreamdata platform are based on a Markov model.
Markov chains (or Markov models) are a common methodology used in attribution problems. It allows us to switch from the heuristic rule-based models to a probabilistic model that takes into account all journeys at the same time to find similarities.
You will also see this method referred to as Chain-Based Models, Funnel Models, or Full-Path Models, essentially covering the same mathematical background - namely Markov Chains.
A Markov Chain describes the customer journey as a series of touchpoints eventually leading to a positive or negative business goal - often referred to as converting (positive) or non-converting (negative) paths. In the Dreamdata platform a business goal is defined through the Stage Model setup.
This aligns with a general picture of the customer journey as a sequence of touchpoints that can come in any order and have varying length. This alignment makes it easier to intuitively understand how the model works, without deep diving into the math.
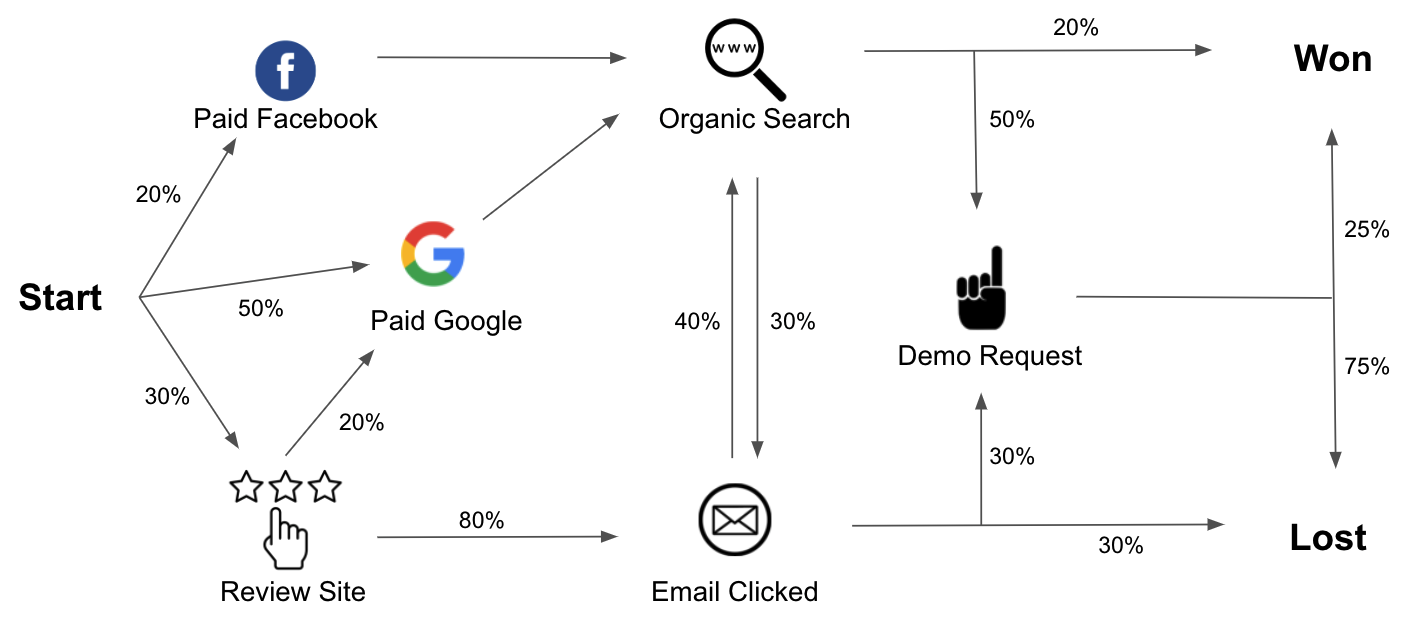
How it works
We use the historical customer journeys leading up to a Stage to make a graph of all customer journeys. This graph is unique to each Stage model.
A touchpoint that is important to generating Leads, might not be equally valuable when the goal is to generate Closed Revenue.
The graph describes how likely an account is to experience a specific touchpoint along the customer journey.
To figure out if a touchpoint is important, we calculate what is commonly referred to as the removal effect. This is the mathematical equivalent of answering: “what would happen if this touchpoint did not exist?”
The rational of the removal effect therefore becomes: If the conversion rate changed a lot if we removed touchpoints X from all the journeys, then X must be important and should receive more credit compared to other touchpoints, that did not cause large changes when removed.
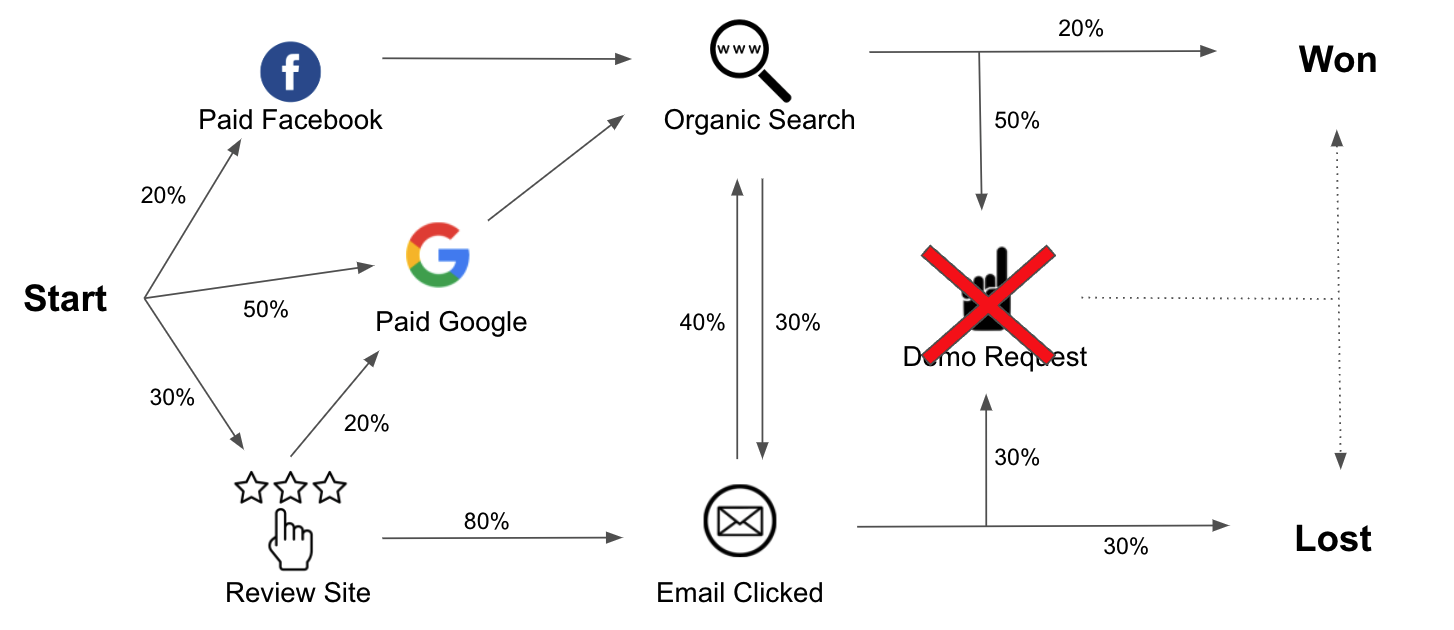
We calculate the removal effect for all touchpoints, thereby determining a weighting of the different touchpoints.
When we add more data, the model will adjust and adapt to your observed journeys.
Credit are assigned based on which touchpoint cause the biggest change when removed.
The fine print part
All data-driven attribution models have a built in problem - aside from the fact that they cannot tell you about the things you cannot find data for.
They look for correlations.
Some methods are more sensitive than others, but the problem is fundamental in any data modelling. In fact, this even goes beyond attribution modelling.
An example to illustrate this:
Many closed deals in B2B will have a meeting somewhere near the end of the journey. This means that most paths leading to a closed deal will have gone through a meeting.
Any model will pick this up and conclude that the meeting must be important. The model is doing what you asked it to: determine what usually happens when you close deals. But we (= the humans) know that the meeting is probably not causing the sale as it is most likely just a meeting to discuss the final terms. The decision was already made. But it correlates with closing.
In this way, any data-driven attribution model is in danger of just telling you what your sales process looks like. As these touchpoints correlate with your sales without causing your sales.
This problem is far more severe in B2B situations, because of the much longer and non-linear journeys observed in this space, compared to its B2C counterpart.
To alleviate this problem to the extent possible, Dreamdata allows for a detailed customization of the data-driven models by giving the user the ability to exclude such touchpoints from the model. Leaving the model to only consider things that potentially could cause sales.
Furthermore, the data-driven attribution model can be combined with (customized) rule-based models such that a certain part of the credit is determined by a rule based model, while we assign the remaining part using the data-driven model. This is done in the data hub --> attribution model inside your Dreamdata instance.